

|
This is the Classic Cognitive Study, so every student has to know it and the Examiner will expect you to be familiar with details. As well as general questions about the Aims, Procedure, Results & Conclusions (APRC), you could get fairly specific questions on how Baddeley tested memory or how the different groups performed. However, remember that there are 3 different experiments reported in the 1966b paper and although we're covering the 3rd one, candidates can in fact write about any of them.
|

CONTENTS
Baddeley (1966b) The First Two Experiments Baddeley's Study AO1 Evaluating Baddeley AO3 Exemplar Essay Baddeley FAQ |
BADDELEY (1966b)
|

|
Aim
To find out if LTM encodes acoustically (based on sound) or semantically (based on meaning). This is done by giving participants word lists that are similar in the way they sound (acoustic) or their meaning (semantic); if the participants struggle to recall the word order, it suggests LTM is confused by the similarity which means that this is how LTM tends to encode. IV This lab experiment has several IVs. (1) Acoustically similar word list or acoustically dissimilar; (2) semantically similar word list or semantically dissimilar; (3) performance before 15 minutes “forgetting” delay and performance after. IVs (1) and (2) are tested using Independent Groups design but IV (3) is tested through Repeated Measures. DV Score on a recall test of 10 words; words must be recalled in the correct order (really, this is a test of remembering the word order, not the words themselves) Sample Men and women from the Cambridge University subject panel (mostly students); they were volunteers. There were 72 altogether, a mixture of men and women. There were 15-20 in each condition (15 in Acoustically Similar, 16 in Semantically Similar). Procedure The participants are split into four groups, according to IV (1) and (2). Each group views a slideshow of a set of 10 words. Each word appears for 3 seconds. In the Acoustically Similar condition, the participants get a list of words that share a similar sound (man, cab, can, max, etc) but the Control group get words that are all simple one syllable words but they do not sound the same (pit, few, cow, pen, etc). In the Semantically Similar condition, the words share a similar meaning (great, large, big, huge, etc) but the Control group get words that are unconnected (good, huge, hot, safe, etc). The participants in all 4 conditions then carry out an “interference test” which involves hearing then writing down 8 numbers three times. Then they recall the words from the slideshow in order. There are four “trials” and (as you would expect) the participants’ get better each time they do it because the words stay the same. The words themselves are displayed on signs around the room so the participants only have to concentrate on getting the ORDER of the words right, not remembering the words themselves. After the 4th trial, the participants get a 15 minute break and perform an unrelated interference task. Then they are asked to recall the list again. This fifth and final trial is unexpected. The words themselves are still on display; it is the order of the words the participants have to recall. Results Baddeley was interested to see whether Acoustic or Semantic Similarity made it harder to learn the words. He compared the scores of the participants in the Similar and Control conditions and paid particular attention to whether they recalled as well in the 5th “forgetting” trial or whether there was a drop-off in scores. 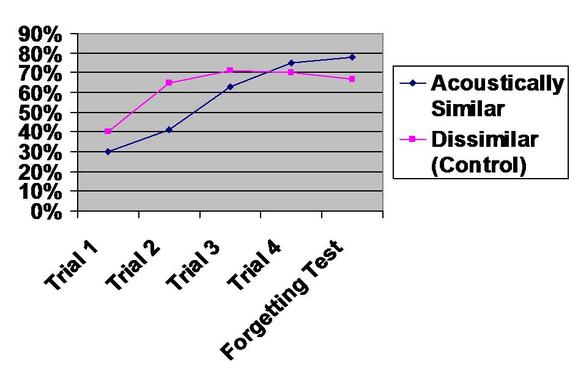
Acoustically similar words seem to be confusing at first, but participants soon “catch up” with the Control group and even overtake them, but this isn’t statistically significant. Notice how LTM is not confused by acoustic similarities – scores on the last test are similar to the 4th trial, suggesting no forgetting has taken place.
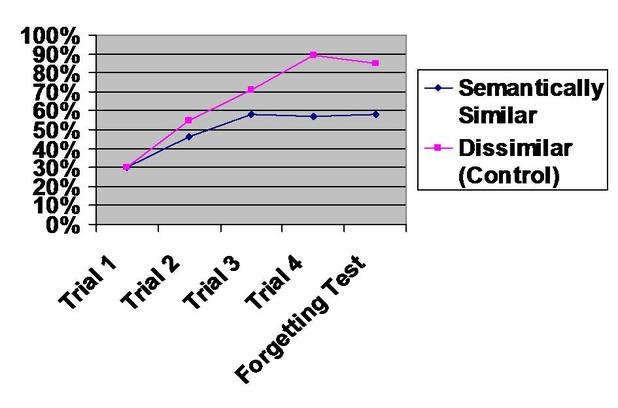
Semantically similar words do seem to be confusing and the experimental group lags behind the Control group. In fact, the experimental group never catches up with the Control group and performs worse overall than the Acoustically Similar group above. Very little forgetting takes place, but scores are lower.
Conclusions Baddeley concludes that LTM encodes semantically, at least primarily. His earlier experiments suggest STM encodes acoustically. This is why LTM gets confused when it has to retrieve the order words which are semantically similar: it gets distracted by the semantic similarities and muddles them up. It has no problem retrieving acoustically similar words because LTM pays no attention to how the words sound. The “slow start” in the Acoustically Similar condition would be because the interference task doesn’t block STM 100% - some of the words linger on in the rehearsal loop. This means in most conditions, the participants’ LTM gets a bit of help from STM. But in the Acoustically Similar condition, STM gets confused by the similar sounds the way that LTM gets confused by similar meanings. It can’t be of much help so this group lags behind the Controls until all the words are encoded in LTM, at which point the two groups finally get similar scores. |

|
Generalisability
Baddeley has a large sample of 72. Any anomalies (people will unusually good or bad memories) will be “averaged out” in a sample this size. This suggests you can generalise from this sample. However, there were so many conditions in this study that each group only had 15-20 people in it. That’s not a lot. Only 15 people did the Acoustically Similar condition. An anomaly could make a difference to scores with numbers that small. The sample was made up of British volunteers. It might be that there is something unusual about the memories of British or the memorable qualities of British words. However this is unlikely. LTM works the same for people from all countries, speaking all languages, so this sample is probably representative. However, a volunteer sample might have more people with parrticularly good memories who enjoy doing memory tests - not representative of people in general. Reliability This is a great example of a reliable study because it has standardised procedures that you could replicate yourself. You wouldn’t need special equipment and you could use exactly the same words that Baddeley used. Baddeley improved the reliability of his own study by getting rid of the read-aloud word lists (some participants had hearing difficulties) and replacing them with slides. Everyone saw the same word for the same amount of time (3 seconds). Application The main application of this study has been for other Cognitive Psychologists, who have built on Baddeley’s research and investigated LTM in greater depth. Baddeley’s use of interference tasks to control STM has been particularly influential. Baddeley & Hitch built on this research and developed a brand new memory model – Working Memory. Another application is for your own revision. If LTM encodes semantically, it makes sense to revise using mind maps that use semantic links. However, reading passages out loud over and over (rote learning) is acoustic coding, but LTM doesn’t seem to work this way, so it won't be as effective. Validity Baddeley took trouble to improve the internal validity of his experiment. He used controls to do this. Rather than getting participants to recall words, he asked them to recall word order (with the words themselves on display the whole time). This reduced the risk that some words would be hard to recall because they were unfamiliar or others easy to recall because they had associations for the participants. However, the ecological validity of this study is not good. Recalling lists of words is quite artificial but you sometimes have to do it (a shopping list, for example). Recalling the order of words is completely artificial and doesn’t resemble anything you would use memory to do in the real world. Baddeley did improve this. For example, he made the 5th “forgetting” trial a surprise that the participants weren’t expecting. This is similar to real life, where you are not usually expecting it when you are asked to recall important information. Ethics There are no significant ethical issues with this study so do not bring up ethics when evaluating it. |

|
EXEMPLAR ESSAY
|
|
|
BADDELEY FAQ
|