

|
WHY INFERENTIAL STATISTICS?
Inferential statistical tests are more powerful than the descriptive statistical tests like measures of central tendency (mean, mode, median) or measures of dispersion (range, standard deviation).
Descriptive statistics analyse the findings from a sample, but inferential statistics tell you how the sample’s results relate back to the target population from which the sample was drawn. This is vital for working out whether the results support the null hypothesis or force you to reject it in favour of the alternative hypothesis.
The Edexcel exam might ask you about the appropriateness of a particular statistical test. 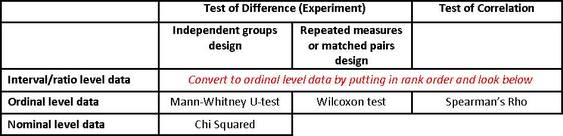
To work out which test to use, you need to understand research design and also levels of data, which are described below.
|

|
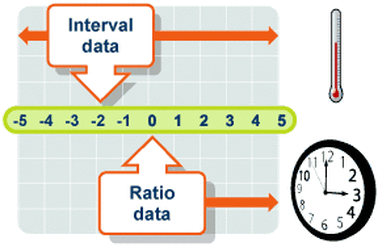
LEVELS OF DATA IN PSYCHOLOGY
|

|
PERFORMING INFERENTIAL STATISTICAL TESTS
|

